
Recent foundation models trained on a tremendous scale of data have shown great promise in a wide range of computer vision tasks and application domains. However, less attention has been paid to the marine realms, which in contrast cover the majority of our blue planet. The scarcity of labeled data is the most hindering issue, and marine photographs illustrate significantly different appearances and contents from general in-air images. Using existing foundation models for marine visual analysis does not yield satisfactory performance, due to not only the data distribution shift, but also the intrinsic limitations of the existing foundation models (e.g., lacking semantics, redundant mask generation, or restricted to image-level scene understanding). In this work, we emphasize both model and data approaches for understanding marine ecosystems. We introduce MarineInst, a foundation model for the analysis of the marine realms with instance visual description, which outputs instance masks and captions for marine object instances. To train MarineInst, we acquire MarineInst20M, the largest marine image dataset to date, which contains a wide spectrum of marine images with high-quality semantic instance masks constructed by a mixture of human-annotated instance masks and model-generated instance masks from our automatic procedure of binary instance filtering. To generate informative and detailed semantic instance captions, we use vision-language models to produce semantic richness with various granularities. Our model and dataset support a wide range of marine visual analysis tasks, from image-level scene understanding to regional mask-level instance understanding. More significantly, MarineInst exhibits strong generalization ability and flexibility to support a wide range of downstream tasks with state-of-the-art performance as demonstrated in teaser figure.
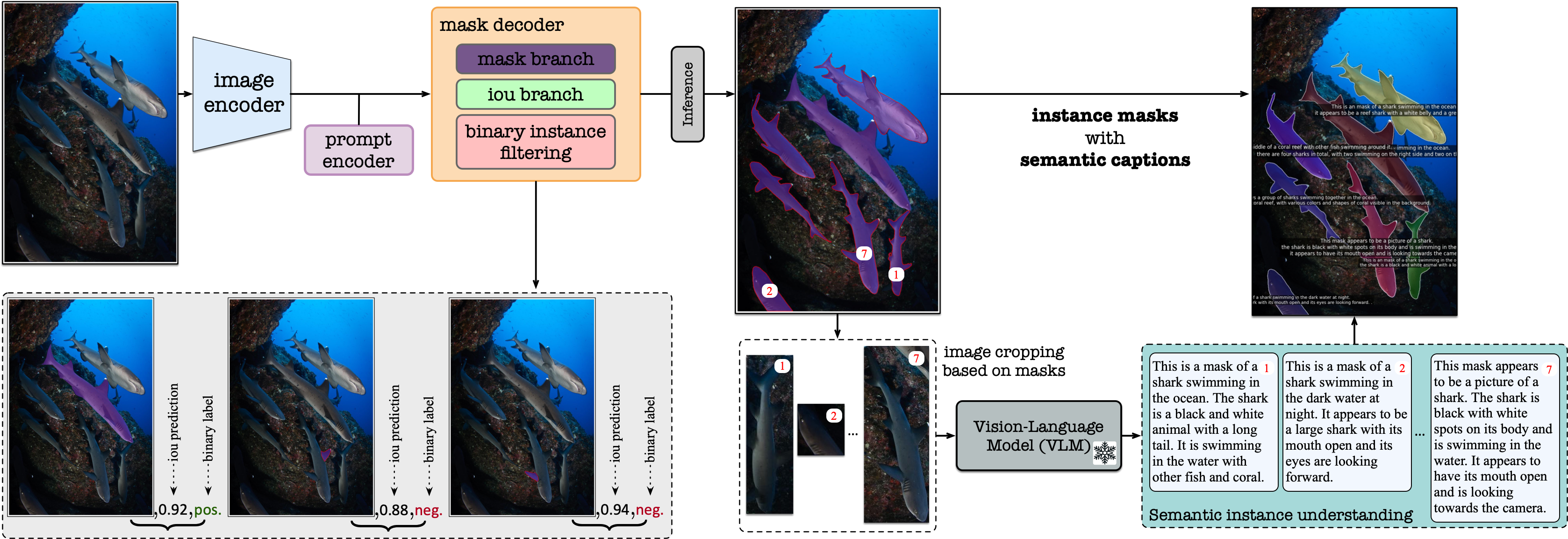
Our marine foundation model has two main stages for predicting instance visual description. The first stage performs instance segmentation to obtain the instance masks, and the second stage performs instance captioning that generates instance captions on the predicted instance masks. To improve the accuracy of the instance masks, we devise a strategy for both training and inference that uses binary instance filtering to remove non-instance masks. We provide an overview of our MarineInst foundation model in framework figure.
We also provide details of MarineInst: We adopt SAM as an effective backbone for instance segmentation with binary instance filtering inside the mask decoder. MarineInst is continuously pre-trained on our MarineInst20M dataset (2.42M images and 19.2M instance masks in total) to better extract efficient marine feature representations. We adopt the combination of point prompt (3 random points inside the mask) and box prompt as the training prompt while ignoring the mask prompt. For instance captioning, we infer frozen VLMs, such as CLIP, BLIP2 and MarineGPT. Our MarineInst is flexible for various VLMs. We adopt BLIP2 and MarineGPT as the main demonstration in this paper. We set the maximum generated tokens to 50 for generating captions.
For comparisons. We include SAM, Semantic-SAM, SSA (SAM+BLIP2+CLIP) and OVSAM for comparison. SAM generates masks under the automatic mode or with prompts. We set the semantic granularity of Semantic-SAM to 3 for automatically producing masks. SSA assigns semantics from BLIP2 to the generated masks from SAM. OVSAM generates masks with point or box prompts.
| Datasets | Categories | Images | Annotation | Non-organism | Diversity | Complicated | Original task and motivation | Img/Inst./Aver. |
|---|---|---|---|---|---|---|---|---|
| Mastr1325 | 3 | 1,325 | Mask | ✔ | Medium | ✘ | Marine obstacle segmentation | 178/215/1.21 |
| Marine Fouling | 3 | 267 | BBOX | ✘ | Low | ✔ | Biological fouling detection | 221/508/2.30 |
| LaRS | 4 | 4,006 | Mask | ✔ | Medium | ✘ | Marine obstacle segmentation | 367/562/1.53 |
| Fish4Knowledge | Foregr. | 27,370 | BBOX | ✘ | Low | ✘ | Fish detection and tracking | 470/470/1.00 |
| MAS3K | 37 | 3,103 | Mask | ✘ | Medium | ✔ | Marine animal segmentation | 553/651/1.18 |
| SUIM | 8 | 1,500 | Mask | ✔ | Medium | ✘ | Underwater scene segmentation | 589/1,091/1.85 |
| Aquarium | 7 | 638 | BBOX | ✘ | Medium | ✘ | Underwater object detection | 632/4,182/6.62 |
| UTB180 | Foregr. | 58,000 | BBOX | ✘ | Low | ✘ | Underwater visual object tracking | 900/900/1.00 |
| TACO | - | 1,500 | BBOX | ✘ | Medium | ✘ | Litter detection | 1,109/2,656/2.39 |
| Brackish | Foregr. | 15,084 | BBOX | ✘ | Low | ✘ | Underwater fish detection and tracking | 1,423/3,168/2.23 |
| FLOW | Foregr. | 2,000 | BBOX | ✘ | Medium | ✘ | Litter detection | 1,825/3,850/2.11 |
| DUO | 3 | 2,227 | BBOX | ✘ | Medium | ✘ | Underwater object detection | 2,170/13,090/6.03 |
| DeepFish | 1 | 39,766 | BBOX | ✘ | Medium | ✘ | Fish detection | 4,396/12,381/2.82 |
| Underwater Garbage | 15 | 416 | BBOX | ✔ | Medium | ✘ | Underwater garbage detection | 4,542/9,386/2.07 |
| CoralNet | 191 | 416,512 | Cate./Point | ✔ | High | ✔ | Sparse point based coral reef identification | 4,615/5,753/1.25 |
| WaterMask | 7 | 4,628 | Mask | ✔ | High | ✘ | Underwater instance segmentation | 4,628/28,410/6.14 |
| IOCFish5k | - | 5,637 | Point | ✘ | High | ✔ | Underwater object counting | 5,382/192,900/35.84 |
| OZFish | Foregr. | 9,242 | BBOX | ✘ | Medium | ✘ | Underwater fish detection | 6,235/38,875/6.23 |
| URPC | 4 | 6,626 | BBOX | ✘ | Medium | ✘ | Underwater object detection | 6,330/38,307/6.05 |
| TrashCan | - | 7,212 | BBOX | ✔ | Medium | ✘ | Underwater trash detection | 6,465/9,855/1.52 |
| Trash-ICRA19 | - | 7,668 | BBOX | ✔ | Medium | ✘ | Underwater trash detection | 7,307/18,822/2.58 |
| MarineDet | 821 | 22,679 | BBOX | ✔ | High | ✔ | Open-marine object detection | 22,679/39,243/1.73 |
| FishNet | 17,357 | 94,532 | Cate./BBOX | ✘ | High | ✔ | Fine-grained fish classification and detection | 48,659/49,774/1.02 |
| FathomNet | - | 109,871 | BBOX | ✔ | High | ✔ | Underwater and deep-sea object detection | 69,909/121,329/1.74 |
| FishNet Open | 34 | 143,818 | BBOX | ✔ | High | ✔ | Fish and non-fish detection | 82,622/285,170/3.45 |
| Total (1st source) | - | 284,206 | ✔ | High | ✔ | Image collection of existing public datasets | 284,206/881,548/3.10 | |
| HK-Reef-Fish | - | 730 | ✘ | Low | ✔ | Fish identification | 729/1,985/2.72 | |
| CoralVOS | - | 60,456 | Mask; | ✔ | Low | ✘ | Coral video segmentation | 750/2,057/2.74 |
| MVC | - | 1,026 | ✘ | Medium | ✘ | Underwater object detection and segmentation | 1,026/3,516/3.43 | |
| Sea Animal | 23 | 13,711 | Category; | ✘ | Medium | ✘ | Sea animal classification | 3,080/7,448/2.42 |
| ImageNet | 38 | 43,907 | Category; | ✘ | Low | ✘ | Scene classification | 3,987/7,175/1.78 |
| MVK | - | 4,872 | ✔ | Medium | ✘ | Marine video retrieval | 4,872/25,077/5.15 | |
| Oceanic Life | - | 7,990 | ✘ | High | ✘ | Collection of Marine Life Imagery | 5,029/20,811/4.14 | |
| Reef-Life-Survey | - | 7,089 | ✘ | High | ✔ | Marine creature identification | 7,075/12,502/1.77 | |
| Corals-of-world | - | 8,217 | ✘ | Medium | ✘ | Coral reef identification | 7,636/17,264/2.26 | |
| Wildfish++ | 2,348 | 103,034 | Category; | ✔ | High | ✘ | Fine-grained fish classification | 9,367/17,075/1.82 |
| FishDB | - | 10,074 | ✘ | Medium | ✘ | Fish species identification | 9,905/18,914/1.91 | |
| Reeflex | - | 15,174 | ✘ | High | ✔ | Marine creature identification | 15,088/61,656/4.09 | |
| Fish-of-Australia | - | 20,795 | ✘ | Medium | ✔ | Fish species identification | 19,269/44,342/2.30 | |
| Youtube | - | 20,935 | ✔ | High | ✔ | Video collection | 20,935/201,290/9.61 | |
| EOL | - | 3,498,763 | ✘ | High | ✔ | Species identification | 23,141/80,128/3.46 | |
| Private data | - | 24,420 | ✔ | High | ✔ | Surveying; Diving; Snorkeling | 24,420/289,898/11.87 | |
| Total (2nd source) | - | 156,309 | ✔ | High | ✔ | Image collection with manual annotations | 156,309/811,138/5.19 | |
| Internet images | - | 35,172 | ✔ | High | ✔ | Image collection (human labeled) | 35,172/194,010/5.52 | |
| Internet images | - | 1,945,714 | ✔ | High | ✔ | Image collection (automatic mask generation) | 1.94M/17.3M/8.89 | |
| Total (3rd source) | - | 1,980,346 | ; | ✔ | High | ✔ | Image collection of Internet images | 1.98M/17.5M/8.84 |
| MarineInst20M | - | 2,420,851 | ; | ✔ | High | ✔ | Instance segmentation and captioning | 2.42M/19.2M/7.93 |
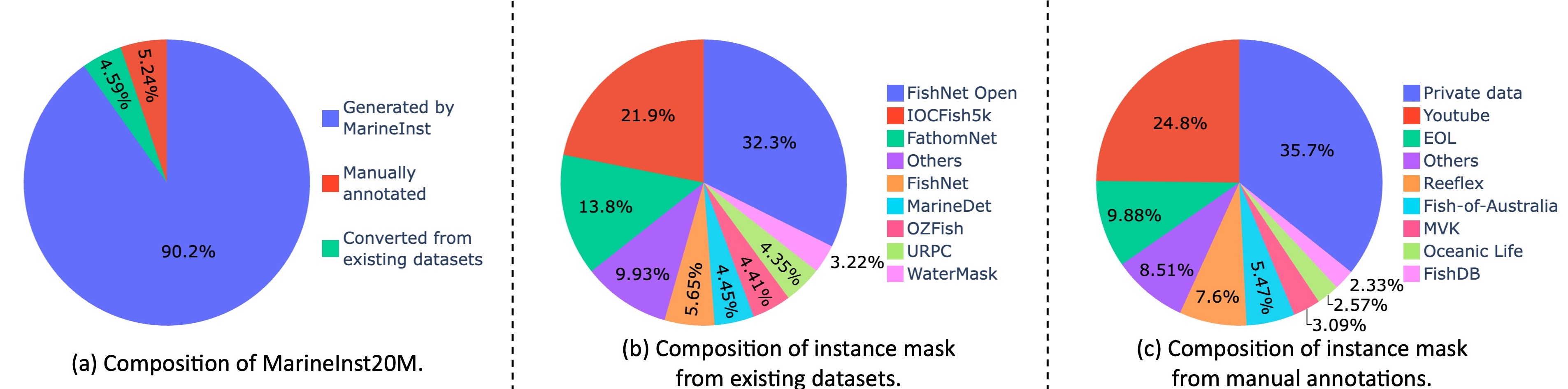
We provide the visualization of the composition of all the instance masks from our MarineInst20M dataset: a) demonstrates the composition of instance masks from three different sources; b) illustrates the composition of the instance masks from the existing public dataset after our conversion; c) shows the composition of the instance masks labeled by the human annotators in this work. For both b) and c), we only visualize the top 8 components for better readability.
We provide the example images with the instance mask visualizations from the existing public datasets after our processing procedures, converting the point or bounding box annotations to instance masks. Please zoom in to check more details.

Instance mask visualization of example images from MarineInst20M dataset. The instance masks are all labeled by human annotators.

Instance mask visualization of example images from MarineInst20M dataset. The instance masks are all automatically generated by our MarineInst model without any prompts.

Visualization of the generated instance masks with comprehensive and detailed semantic instance captions. Please zoom in to check more details.
The world cloud visualization of the top 1,000 words in all the extracted phrases from the alt-texts of the public Internet images.

MarineInst could effectively address the over-segmentation and partial-segmentation issues of SAM and Semantic-SAM. Meanwhile, MarineInst could generate meaningful and comprehensive semantic captions faithful to each generated instance mask, while others cannot.

Comparison between MarineInst and the existing SOTA algorithms. Both SAM and MarineInst generate masks based on automatically generated grid points. SSA yields semantic predictions based on the automatically generated masks by SAM. We set the semantic granularities of Semantic-SAM to 3. OVSAM is inferred by the box prompts. Please zoom in to see more details.

Head-to-head comparison between SAM and MarineInst on instance mask generation. The
★ indicates the automatically generated grid point prompts. SAM suffers from over-segmentation and partial-segmentation issues, generating redundant meaningless masks. MarineInst demonstrates a stronger ability than SAM on instance mask generation.
(a) Image storytelling based on MarineInst. (b) Marine text-to-image synthesis based on stable diffusion model (stable-diffusion-v1-5).

We report the marine text-to-image synthesis results under two settings: a) without fine-tuning and b) with fine-tuning on our MarineInst20M dataset. The reference images from the required marine species have also been provided for the readers to better compare the synthesis performance. Best viewed in color.

We optimize our MarineInst to generate comprehensive and detailed semantic instance captions for each generated instance mask. Then we utilize ChatGPT-3.5 to generate the merged caption as the image-level caption based on the generated instance captions. GPT-4V is included for comparison, where texts in
green are correct responses and red are wrong responses.
The results of instruction-following instance understanding and segmentation. Texts in green are correct responses and red are wrong responses.

The instruction-following instance understanding results of MarineInst under two settings: 1) single mask and 2) multiple masks with assigned mask IDs. The texts in
green are correct responses and the texts in red are wrong responses.
There are still some hallucinations in the generated semantic captions for the instance mask. Best viewed in color.
@article{ziqiang2024marineinst,
title={MarineInst: A Foundation Model for Marine Image Analysis with Instance Visual Description},
author={Ziqiang Zheng, Yiwe Chen, Huimin Zeng, Tuan-Anh Vu, Binh-Son Hua, Sai-Kit Yeung},
journal={European Conference on Computer Vision (ECCV)},
year={2024},
publisher={Springer}
}Thanks to ...